

De datos crudos a información curada: data-warehousing en Clay
En Clay nos dedicamos a ayudar a emprendedores de todos los tamaños a gestionar las finanzas y contabilidad de sus empresas. Para esto, integramos información relevante de diversas instituciones financieras, el Servicio de Impuestos Internos (SII) y otros actores clave en la operación financiera y contable.
La mayoría de estas instituciones no disponibilizan esta información de manera que sea fácilmente integrable con otros sistemas, por lo que gran parte de nuestro trabajo consiste en construir scrapers, realizar el parsing, interpretar y traducir esa información a un modelo común. Uno de los productos de este enorme esfuerzo de integración es la conciliación financiera automatizada y la generación de libros contables.
Hasta ahora, la audacia y el talento de nuestro equipo nos han permitido sortear los desafíos y la complejidad de mantener una integración tan grande y heterogénea, sin comprometer el nivel de servicio que ofrecemos a nuestros clientes. Sin embargo, Clay ha crecido mucho, y con ello ha aumentado el desafío cuando surgen problemas en la calidad de los datos.

Por otra parte, diversos procesos internos se benefician del uso que Clay hace de Clay (sí, gestionamos nuestras finanzas y contabilidad usando Clay). Esto nos sirve como punta de lanza para identificar nuevas funcionalidades que podemos ofrecer a nuestros clientes. Para lograrlo, es esencial consumir y transformar la información contable de Clay sin fricciones y de manera consistente entre los distintos equipos.
A menudo, más de un equipo necesita observar KPIs ligeramente distintos, pero que deben ser consistentes entre sí para mantener una comunicación efectiva dentro de la organización. Este tipo de problemas es difícil de resolver con data pipelines descentralizados o cálculos ad-hoc. Ante estos desafíos, buscamos herramientas y patrones tecnológicos que nos permitan abordarlos con precisión y calma.
Áreas críticas a mejorar
Después de analizarlo en profundidad, identificamos dos áreas críticas a mejorar: primero, la transformación de los datos en un formato que sea comprensible para el negocio y el caso de uso, lo que nos permita catalogarlos como información correcta o incorrecta. Esto es clave, ya que, en última instancia, la calidad de los datos es evaluada por personas, quienes deben poder entenderla y validarla. Incluso en un área tan técnica como la contabilidad, los balances y asientos contables son conjuntos de información que deben ser comprensibles para humanos con cierto conocimiento en la materia.
El segundo aspecto a mejorar es que, una vez que los datos se encuentran en un formato comprensible, debemos ser capaces de aplicar pruebas y controles que nos alerten sobre problemas en su calidad. Si probamos el código antes de pasarlo a producción, ¿por qué no deberíamos aplicar el mismo rigor con los datos que integramos, que usamos para decisiones críticas y que están sujetos a ciertos supuestos?
Con lo anterior, las pruebas de calidad no solo toman formas básicas como inspeccionar duplicacion de datos, nulls donde no deben existir o tipos de datos incorrectos, sino que tambien como test ácidos sobre indicadores de negocio que hacen sentido a los consumidores de la información.
Nuestra solución: data-warehousing
Parte de la solución a esta problemática está en el patrón de ingeniería de datos “Write-Audit-Publish” (WAP), utilizado por Netflix, así como en el concepto bien conocido de Data Warehousing. Al final, la gestión de la calidad de la información es un problema tan antiguo como la humanidad misma, y existen múltiples enfoques para abordarlo.

En nuestro caso, decidimos implementar un data warehouse en PostgreSQL como el centro de gestión y almacenamiento de datos “curados”, utilizando herramientas sencillas: Python para la ingestión de datos y dbt para la transformación y prueba de los mismos.
La ingestión de datos requiere flexibilidad, especialmente al parsear distintas fuentes, principalmente datos transaccionales en MongoDB, que, como muchos saben, tiene un schema flexible. Por ello, optamos por usar Python puro para esta tarea.
Los servicios de ingestión comparten la mayoría del código y utilizan polimorfismo en un esquema similar al “strategy pattern” para manejar las particularidades de cada fuente de datos. Estos servicios corren sin problemas en AWS Lambda, y la orquestación de sus instancias se gestiona con AWS Step Functions. Este stack nos permite cubrir las necesidades de ingestión a un costo operativo muy bajo, en comparación con otros servicios de infraestructura de esta magnitud.
Una vez que los datos han sido publicados en el schema de entrada del data warehouse, dbt nos ayuda a transformarlos. Como mencionamos antes, un desafío clave es que las distintas fuentes de datos adopten la “ontología” y sentido “semántico” que el negocio le da a la información, y en esto, dbt sobresale. La capacidad de ordenar las transformaciones en nodos llamados “modelos” y orquestarlos como un grafo dirigido, manipulando los datos directamente en PostgreSQL, es extraordinaria.
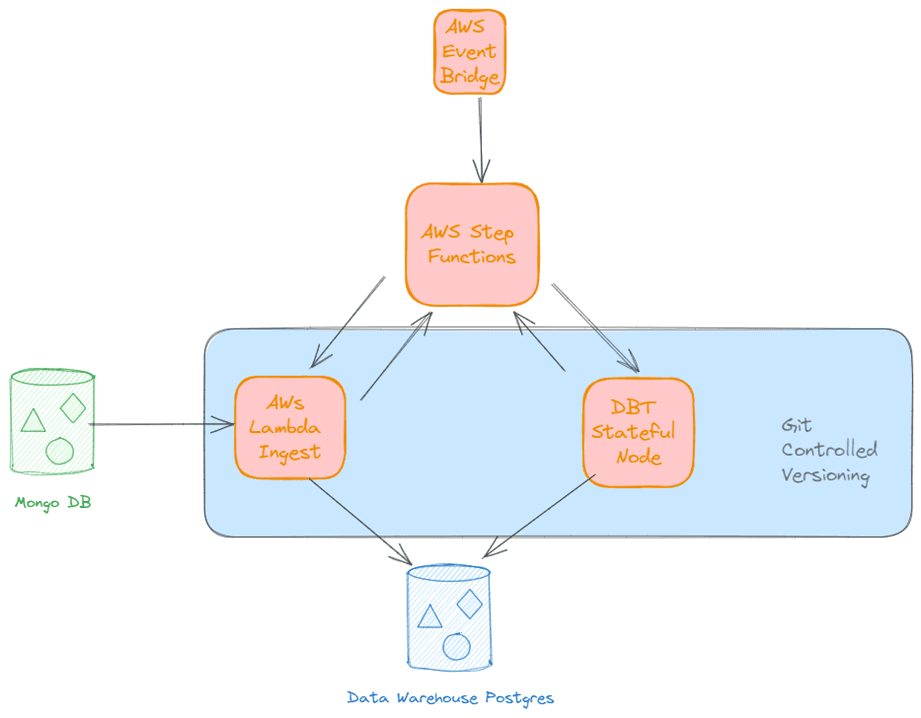
Esto nos permite construir dos capas de modelos (además de la capa que representa las fuentes de datos): una capa donde se encuentran las estructuras atómicas que tienen sentido para el negocio, y otra capa donde la información está lista para el consumo final. Estas capas están materializadas en tablas distribuidas en tres schemas dentro de la base de datos, lo que facilita la organización y comprensión, tanto para humanos como para sistemas automatizados.
Pruebas de datos
En cuanto a las pruebas de datos, dbt también es fundamental. Al tener los datos ya transformados, es sencillo crear múltiples pruebas para garantizar la calidad de los mismos. Estas pruebas se implementan como consultas SQL con resultados esperados tipo “assertions”, que devuelven filas cuando algún registro no pasa el estándar.
Los resultados de estas pruebas se almacenan en tablas dentro de un cuarto schema dedicado a este propósito. Dado que gran parte de nuestra información transaccional proviene de MongoDB, es común que ciertos campos adopten valores que alteran cálculos aguas abajo en el pipeline. Las pruebas de dbt nos han ayudado enormemente a identificar estos problemas.
Con este stack sencillo, en aproximadamente dos meses pasamos de identificar el desafío a usar esta solución en producción, primero probando datos clave a una escala que no habíamos logrado antes y, segundo, teniendo una fuente confiable y curada para el business intelligence de la empresa.

En este corto tiempo, hemos reducido el esfuerzo necesario para resolver problemas de datos, disminuido significativamente los tickets de nuestros clientes y nos ha inspirado a avanzar en otras automatizaciones. Si te interesa contribuir y ser parte de estos emocionantes desafíos, ¡no dudes en postular a nuestras vacantes! Tenemos una ambiciosa agenda futura en ingeniería de datos e inteligencia artificial para ayudar a que los emprendedores gestionen sus finanzas de manera extraordinaria.
En 20 minutos sabrás si la solución que necesitas está en Clay.
Experimenta la tranquilidad de tener todo en orden.
